Data mining in healthcare: How it works, key benefits, and privacy risks



Hospitals and public health organizations collect enormous amounts of data, including patient records, lab results, imaging scans, and more. The challenge for healthcare providers and researchers is turning this information into useful insights.
Data mining in healthcare addresses this challenge by helping healthcare providers identify useful patterns in medical and operational data, improve efficiency, and make better clinical and operational decisions.
What is data mining in healthcare?
Data mining in healthcare is the process of extracting useful patterns, trends, and insights from large sets of medical data that would be difficult or impossible to identify manually. It applies statistical and computational techniques to that information to find connections that can help healthcare providers predict disease risk, personalize treatment, reduce operational costs, and make better-informed clinical decisions.
In practice, this can include analyzing electronic health records to identify patients at higher risk of developing conditions such as diabetes or heart disease, using past imaging and lab results to help detect diseases earlier, or studying treatment outcomes across large patient groups to determine which therapies tend to work best for specific populations.
Public health agencies can use it to track the spread of infectious diseases and detect outbreaks earlier. Insurers and healthcare administrators may also apply data mining to identify billing irregularities, reduce fraud, and improve resource planning, such as staffing and bed allocation.
How data mining differs from data analytics
Data analytics usually focuses on examining data to answer specific questions, such as how many patients were treated in a given period or how long a procedure typically takes.
Data mining goes further by looking for patterns that aren’t obvious. It often starts with a large dataset and uses algorithms to find meaningful relationships automatically. For example, it might reveal that patients with certain risk factors are more likely to be readmitted to the hospital, even if that connection wasn’t previously known.
In healthcare, both approaches are important. Data analytics helps organizations understand performance and outcomes, while data mining helps them gain new insights that can improve care and efficiency.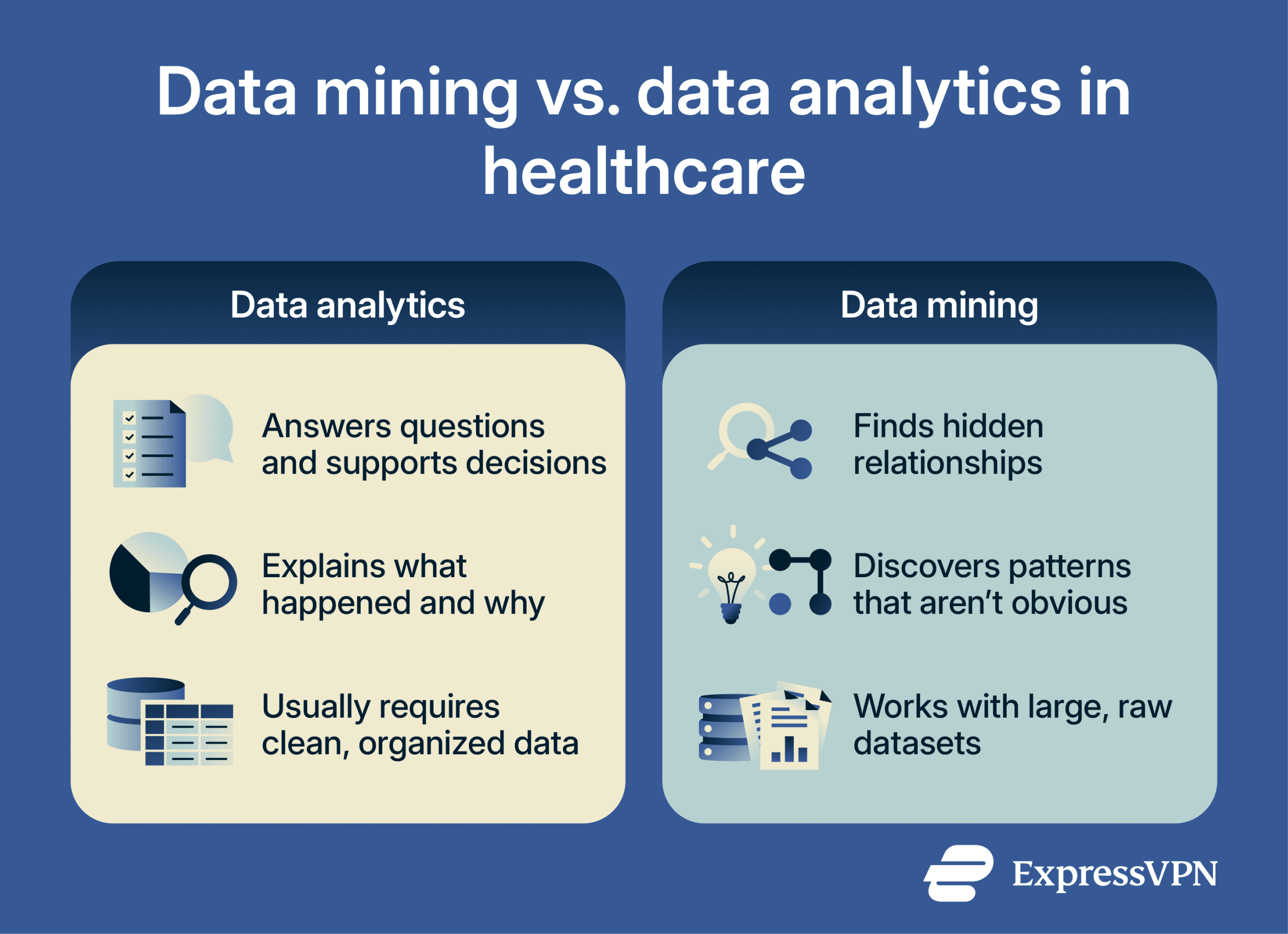
How data mining works in healthcare
Data mining in healthcare follows a structured process. Although the exact methods vary across organizations and use cases, most healthcare data mining projects follow three main stages:
- Data collection and integration
- Pattern discovery and analysis
- Turning insights into action
Data collection and integration
Data collection and integration start with gathering data from across the healthcare system. This includes structured data, such as diagnosis codes, medication records, and lab values, as well as unstructured data like clinical notes, imaging reports, and patient feedback forms.
One of the biggest challenges at this stage is integration. Healthcare data is often stored across multiple, disconnected systems. Before any large-scale analysis can take place, this data needs to be pulled together into a unified format.
This is typically done through a process called extract, transform, load (ETL), where data is extracted from its source systems, converted into a consistent format, and loaded into a central data repository or data warehouse. Standards like Health Level Seven (HL7) and Fast Healthcare Interoperability Resources (FHIR) help facilitate this process by providing common frameworks for how healthcare data is structured and shared across systems.
Before the data can be used, it also needs to be cleaned and prepared. Data cleaning and preparation may include removing duplicate records, correcting errors, standardizing formats, and filling in missing values.
Pattern discovery and analysis
Once the data is prepared, analytical models are applied to search for patterns, correlations, and anomalies. Depending on the goal, this might involve supervised learning, where a model is trained on labeled historical data to make predictions, or unsupervised learning, where the model identifies natural groupings or structures within the data without predefined categories.
At this stage, data scientists and clinical informatics specialists work together to select the right techniques for the problem at hand. A model designed to predict patient deterioration in an intensive care unit, for example, requires different inputs and methods than one built to detect duplicate insurance claims.
The output of this stage is typically a set of identified patterns or a predictive model that can be tested against new data.
Turning insights into action
The final stage of healthcare data mining is applying the results to support decisions. Insights are usually presented through reports, dashboards, or alerts.
Even when data mining provides useful insights, decisions are typically reviewed by healthcare professionals before being applied. Healthcare professionals must consider medical judgment, ethical guidelines, and patient consent before acting on the results.
This stage also involves ongoing monitoring. Models might lose accuracy over time if they aren’t updated. Patient populations shift, treatment protocols change, and new data sources become available. Healthcare organizations need processes in place to regularly retrain and update their models to ensure the insights they generate remain reliable.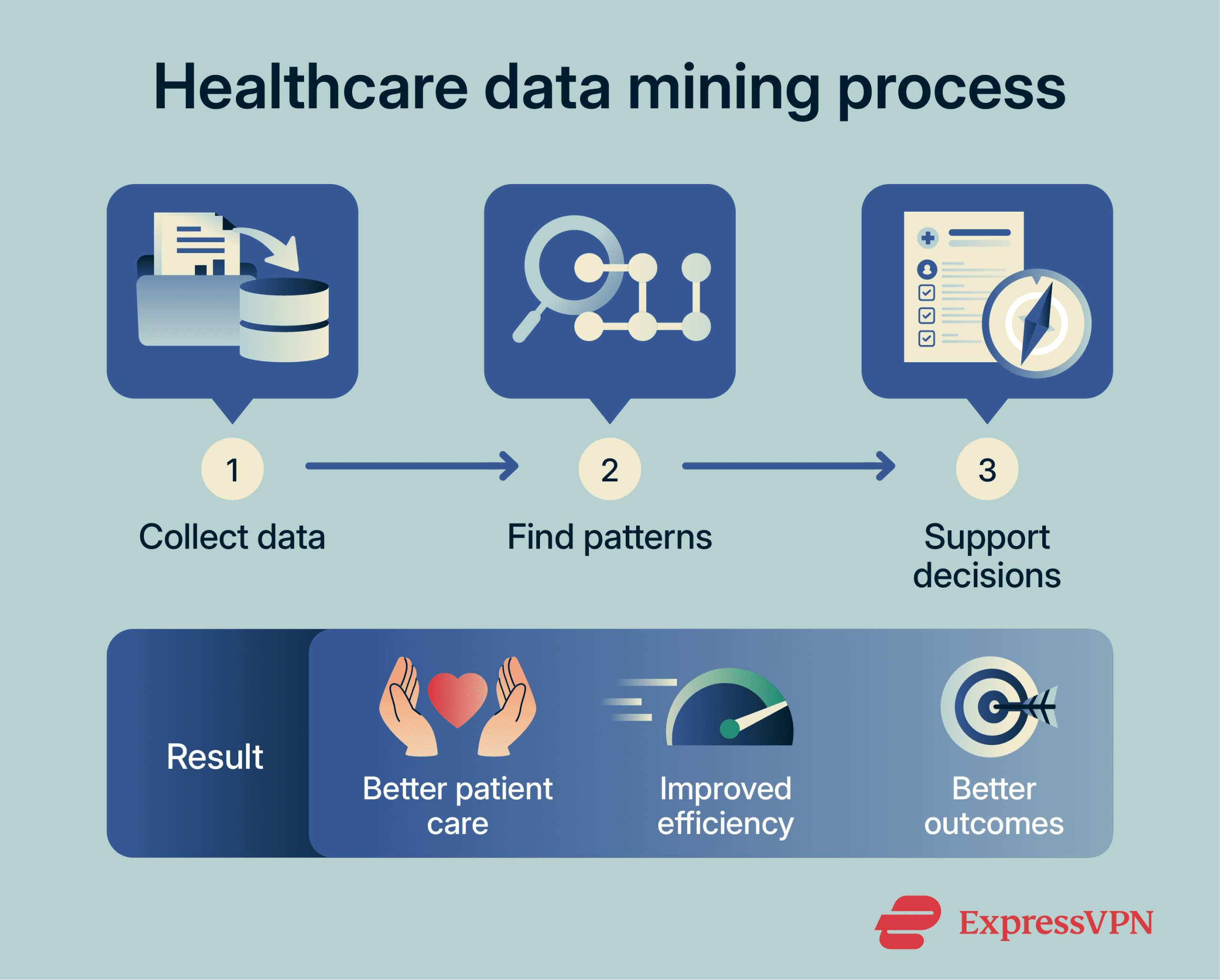
Top data mining techniques in healthcare
Healthcare organizations use several data mining techniques, with each technique designed for a specific purpose, such as identifying patterns, predicting outcomes, or detecting unusual activity.
Below are some of the most common data mining techniques used in healthcare systems.
Classification
Classification is a technique that places patients or records into predefined categories based on specific characteristics or data patterns. It’s commonly used to diagnose diseases, assess patient risk levels, and determine whether a patient is likely to respond to a particular treatment.
For example, a classification model might analyze a patient's age, medical history, symptoms, and lab results to predict whether they are at low, moderate, or high risk of developing type 2 diabetes.
Clustering
Clustering groups similar data points together without using predefined categories. For example, clustering can help group patients with similar symptoms, treatment responses, medical histories, or disease progression patterns. Researchers may use this approach to identify subtypes of a disease or to understand how different patient groups respond to the same treatment.
Clustering is also useful for population health analysis. By grouping patients based on shared characteristics, healthcare providers can design targeted prevention programs or improve care for specific groups.
Association rule mining
Association rule mining looks for relationships between different variables in a dataset. It helps identify events or conditions that occur together more frequently than would be expected by chance.
This technique can reveal links between symptoms, diagnoses, medications, or outcomes. For example, association rule mining might show that patients with certain risk factors are more likely to develop complications after a procedure. It can also help identify combinations of medications that are frequently prescribed together and flag cases where co-prescribing is associated with adverse outcomes.
Predictive modeling
Predictive modeling uses historical data to estimate what is likely to happen in the future. It draws on a range of statistical and machine learning (ML) methods, including regression analysis, decision trees, and neural networks, to identify the factors most strongly associated with a particular outcome and use them to make predictions about new cases. This technique is particularly useful in healthcare because it can support early intervention and planning.
For example, predictive models can estimate the likelihood of disease progression or treatment success. Public health agencies may also use predictive modeling to forecast the spread of illnesses based on past trends.
Operationally, predictive modeling supports forecasting of patient demand, staffing needs, and resource allocation.
Outlier detection
Outlier detection identifies data points that fall significantly outside an expected range or pattern. In healthcare, unusual patterns may indicate errors, rare conditions, or potential misuse of systems.
On the clinical side, outlier detection can flag unusual patient readings, such as an unexpected spike in a lab value, that may warrant further investigation.
On the administrative side, it helps identify billing patterns that deviate from the norm, such as unusually high claim volumes, duplicate submissions, or charges for services inconsistent with a patient's documented condition.
Because healthcare data can vary widely between patients, outlier detection must be used carefully. Unusual results don’t always mean something is wrong, but they can signal the need for closer review.
Cybersecurity risks in healthcare data mining
Medical information is among the most sensitive categories of personal data. Records can reveal details about a person's physical and mental health, reproductive history, substance use, genetic makeup, and more. If this information is accessed without permission or used outside its intended purpose, the consequences can be serious and far-reaching. By affecting a person’s employment, insurance coverage, housing opportunities, or personal relationships, unauthorized disclosure can lead to discrimination, stigma, emotional distress, or financial harm.
The risks are even greater because health data is often deeply personal and difficult, if not impossible, to change once exposed. Unlike a password, a diagnosis, genetic trait, or medical history cannot simply be reset.
Below are some of the most common cybersecurity risks associated with healthcare data mining.
Data breaches and unauthorized access
Healthcare records contain names, dates of birth, Social Security numbers (SSNs), insurance details, and medical histories. This makes them considerably valuable on illicit markets, and healthcare organizations are often targeted by data theft campaigns as a result.
Additionally, data mining projects often require combining information from different sources, which increases the number of systems that may be vulnerable.
Data breaches can occur on vulnerable systems through a range of vectors, including weak or compromised credentials, misconfigured databases, unsecured APIs, unpatched software, phishing attacks, misconfigured servers, and vulnerabilities in third-party software.
Healthcare organizations can reduce the risk of data breaches through a mix of technical security controls, strict policies, and staff awareness. These include access controls, data encryption, regular security updates, employee training, and clear rules on how patient data can be stored, shared, and accessed.
Ransomware
Ransomware attacks, such as those carried out by the Conti group, are a common cybersecurity threat in the healthcare sector. In these attacks, malicious software encrypts an organization's analytics platforms and research databases, rendering them inaccessible until a payment is made.
Since healthcare data mining relies on continuous access to data warehouses, analytics tools, and research databases, ransomware attacks can interrupt data processing, reporting, and research activities, delaying insights, and affecting decision-making. Organizations may need to restore datasets from backups, rebuild affected servers, or temporarily suspend analytics operations while systems are secured.
Preventive measures often include regular backups, network segmentation and monitoring, and staff training to recognize suspicious activity.
Insider threats and misuse of sensitive data
Employees, contractors, or partners who have legitimate access to healthcare systems may accidentally expose data through poor security practices or use it in ways that aren’t authorized.
Insider risks might include sharing data without proper approval, using personal devices that aren’t secure, or accessing records that aren’t needed for a specific task.
Since data mining projects often require access to large datasets, it’s important to control who can view, copy, or modify information. Healthcare organizations can also reduce the risk of insider threats through zero-trust data protection, audit logging, proper data governance policies, and regular reviews of user activity.
Third-party security risks
Healthcare data mining frequently involves third parties like software vendors, cloud providers, analytics platforms, and research partners. When data is shared with third parties, the overall security of the system depends on the protections used by each participant.
If a vendor or partner has weaker security controls, it may create a risk even when the healthcare organization’s own systems are well protected. For this reason, organizations often require contractual safeguards and compliance checks before sharing sensitive data.
Re-identification risks in de-identified data
Healthcare data used for analysis is often de-identified, meaning that direct personal identifiers such as names and SSNs are removed. This allows researchers and analysts to work with large datasets without immediately revealing a patient’s identity.
However, de-identified data can sometimes be linked back to individuals when combined with other information. For example, rare conditions, unusual treatment dates, or geographic details may make it possible to identify someone even without their name being included.
Challenges of data mining in healthcare
Organizations working with large and complex medical datasets often face a range of technical, operational, and ethical challenges that can affect the quality and reliability of the insights produced. Because of this, organizations typically require reliable processes and strong safeguards before data mining results can be used in practice.
Below are some of the most common challenges healthcare organizations face when applying data mining techniques.
Interoperability across healthcare systems
Interoperability is a challenge across much of the healthcare sector. In many cases, hospitals, clinics, laboratories, and insurers use separate platforms with different data standards.
For data mining, limited interoperability means that analytical models are often built on data from a single institution or system. A predictive model trained on data from one hospital network may not perform as reliably when applied to patients at a different facility with different demographic characteristics or clinical practices.
Addressing this often requires technical solutions, policy frameworks, and organizational agreements that govern how data can be shared across institutional boundaries.
Bias and model accuracy
When training data contains errors, gaps, or uneven representation of certain groups, the analysis may produce biased or inaccurate results.
For example, if a dataset includes more information from one patient group than another, predictions may not be equally reliable for all populations. In healthcare, this can affect risk assessments, treatment recommendations, or research findings.
Detecting and mitigating bias requires ongoing attention throughout the model development process, including careful examination of training data, regular performance evaluation across different subpopulations, and clear protocols for when and how model outputs should inform clinical judgment.
The future of data mining in healthcare
Data mining in healthcare is evolving rapidly, driven by advances in computing power, the growing availability of digital health data, and the increasing integration of AI into clinical and operational workflows. Below are some trends that are likely to shape the future of healthcare data mining.
The growing role of AI and machine learning
AI and ML are becoming increasingly important in how healthcare data is analyzed. Where traditional data mining techniques rely on predefined rules or statistical models, ML approaches can identify complex, nonlinear patterns across large datasets without being explicitly programmed to look for them.
Large language models (LLMs) are increasingly being applied to unstructured clinical data, such as physician notes, discharge summaries, and radiology reports, which have historically been difficult to incorporate into structured data mining workflows.
The Food and Drug Administration (FDA) has also reported a significant and sustained increase in the number of AI-enabled medical devices being authorized for marketing in the U.S., reflecting growing institutional adoption of these technologies across the healthcare sector.
Innovations in predictive healthcare
Predictive healthcare in particular is an area where data mining is expanding. The FDA notes that AI-based tools are being used in areas such as early disease detection, diagnosis, prognosis, and risk assessment, all of which depend on analyzing large volumes of health data for patterns that support earlier or more informed decisions.
Additionally, predictive modeling in healthcare is becoming more precise as richer data sources are integrated into analytical workflows. Genomic data, data from wearable health monitors, and real-world evidence gathered from electronic health records are increasingly being combined to build models that can account for a wider range of biological, behavioral, and environmental factors.
The National Institutes of Health (NIH) All of Us Research Program, which is building one of the largest and most diverse biomedical datasets ever assembled, is explicitly designed to support this kind of multi-dimensional predictive research. Findings from programs like this might help improve the accuracy of risk prediction models across a range of conditions, particularly for patient populations that have historically been underrepresented in clinical research.
The rise of personalized medicine
Rather than applying population-level treatment protocols to individual patients, personalized medicine uses data about a patient's genetic profile, lifestyle, environment, and clinical history to inform decisions that are specific to them.
Data mining plays a key role in making this approach scalable. Progress in this area is already visible in oncology, where genomic data mining is used to identify tumor characteristics that predict response to specific therapies, enabling more targeted treatment selection. The broader application of these principles across other disease areas is an active focus of research at institutions including the National Institutes of Health (NIH) and leading academic medical centers.
FAQ: Common questions about data mining in healthcare
What are the biggest cybersecurity threats to healthcare data?
Can de-identified healthcare data still create privacy risks?
Why is patient consent important in healthcare data mining?
How does data mining help detect fraud in healthcare?
What should providers look for in secure data mining tools?
Take the first step to protect yourself online. Try ExpressVPN risk-free.
Get ExpressVPN